Il principale valore del machine learning è la sua capacità di elaborare set di dati enormi che sono ben oltre la portata delle capacità umane. Si tratta di una sorta di cilindro magico in cui i dati grezzi e non strutturati entrano e vengono fuori intuizioni cliniche in grado di aiutare i medici a pianificare e fornire cure migliori e a un costo inferiore. Se da una parte l’unico limite in futuro per quanto riguarda i benefici del machine learning sembra essere il cielo, dall’altra la costruzione di questi algoritmi complessi richiede tempo e sembra oggi essere un percorso rischioso e pieno di passi falsi.
In gergo la tipologia di processo alla base del machine learning viene definito “garbage in, garbage out“, ovvero un processo in cui la qualità dell’output che otteniamo è inevitabilmente legata alla qualità degli input che utilizziamo. Questo vuol dire che se in partenza utilizziamo dataset sporchi e poco chiari, anche i risultati che otterremmo lo saranno. Senza nuovi modi per elaborare e comprendere i dati che stiamo raccogliendo, il processo decisionale diventerà inefficace e le intuizioni cliniche che otterremo non potranno essere utilizzate per produrre nuova conoscenza e quindi cambiare i nostri processi di cura.
Se è evidente che l’utilizzo dell’intelligenza artificiale nell’assistenza sanitaria ne migliorerà la qualità riducendone i costi (e rendendola così più accessibile), è altrettanto evidente come questa abbia portato già da oggi anche nuove sfide da affrontare.
L’alba dell’ingegneria della conoscenza
Il ruolo principale del machine learning è quello di analizzare e imparare da set di dati in modo da costruire modelli predittivi. In parole povere, così come abbiamo dedicato gli ultimi vent’anni a costruire motori di ricerca, ora stiamo cercando di costruire motori di conoscenza. A differenza dei motori di ricerca, il compito principale dei motori di conoscenza non è solo il rilevamento, ma anche la previsione di informazioni rilevanti, che nel caso dell’healthcare possano portare ad esempio a una pianificazione più efficace delle cure a lungo termine per i pazienti. Non si tratta quindi solo di raccogliere e organizzare informazioni, ma di dare loro un significato che sia possibilmente comprensibile da chi dovrà poi utilizzarle.
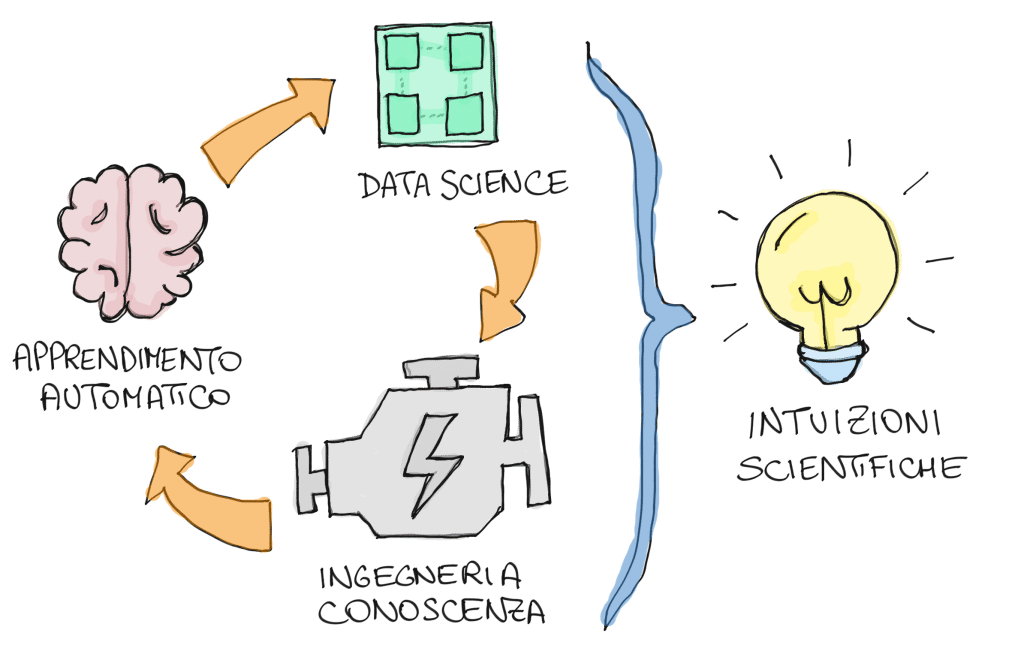
Il ruolo principale della scienza dei dati (data science) è quello di estrarre la conoscenza dalle informazioni rilevanti del paziente; serve come collegamento tra l’apprendimento automatico e l’ingegneria della conoscenza. L’estrazione della conoscenza richiede competenze sia nelle scienze mediche che nell’apprendimento automatico, portando ad un ulteriore sviluppo delle tecniche di apprendimento automatico.
Il ruolo principale dell’ingegneria della conoscenza è quello di costruire un sistema esperto per una diagnosi corretta. L’ingegnere della conoscenza svilupperà un prototipo di sistema esperto utilizzando la conoscenza estratta dalla scienza dei dati. La sfida chiave qui è l’induzione di regole dai dati basati sull’ontologia medica per ottenere una comunicazione efficace con i medici.
In sintesi, mentre il ruolo dell’apprendimento automatico si sta espandendo, credo stia diventando sempre più chiaro che lo sviluppo di nuove professioni (gli ingegneri della conoscenza) sarà necessario per avere “conversazioni significative” tra data scientist e medici.
L’industria ha iniziato a chiamare questi lavoratori ingegneri della conoscenza (KE) invece di analisti della conoscenza (KA). Il KE ha accesso non solo agli strumenti della scienza dei dati (compresi gli algoritmi di apprendimento automatico), ma anche all’esperienza medica, alla conoscenza del dominio e alle tecniche di recupero delle informazioni.
Queste competenze sono cruciali per assicurarsi che l’IA sia usata nel modo più efficace possibile.
Il ruolo dell’ingegneria della conoscenza nell’assistenza sanitaria
Secondo alcuni dati della National Academies, entro il 2050 il 60% di tutti gli americani avrà 65 anni o più. Questo dato presenta un enorme problema per quanto riguarda l’assistenza sanitaria, in quanto il costo del trattamento dei pazienti con malattie croniche è diventato costoso e con l’invecchiamento della popolazione, questo non potrà che peggiorare.
Se il ruolo chiave del machine learning non è solo il rilevamento, ma la previsione di informazioni rilevanti per il paziente in grado di portare a una pianificazione più efficace delle cure a lungo termine, allora è bene sottolineare come questi dati siano attualmente inaccessibili per i medici e possono essere nascosti sotto altri dati che possono essere non facilmente valutabili. Il ruolo dell’ingegneria della conoscenza sarà quindi quello di costruire un sistema “esperto” e utile per effettuare una diagnosi corretta. Il machine learning sarà incorporato nell’ingegneria della conoscenza, e il tutto diventerà un asse imprescindibile del lavoro clinico.
L’industria sanitaria ha fatto notevoli progressi con lo sviluppo di modelli predittivi, tuttavia c’è ancora molto lavoro da fare per migliorare la precisione predittiva e la loro accuratezza nel servire i pazienti.
Il problema della delega (e della fiducia)
Se da una parte l’uso dell’IA nella sanità ha molti vantaggi rispetto ai metodi attuali (come fornire diagnosi più accurate, raccomandare trattamenti migliori, ridurre gli errori medici, accorciare il tempo di trattamento, spendere meno soldi per l’assistenza sanitaria), dall’altra è inutile nascondere come le implicazioni etiche e sociali che nascono dalla sua applicazione nella sanità sono oggetto di grande preoccupazione.
A mio avviso uno dei problemi principali (e di certo quello al momento più trascurato) è il fatto che i pazienti possano perdere la fiducia nei loro medici se questi non mostreranno una completa padronanza degli insight clinici ottenuti utilizzando la tecnologia AI. Il tutto, in un contesto che dall’avvento di internet ha già visto entrare in crisi il rapporto tradizionalmente asimmetrico tra medico e paziente. I medici sono attualmente visti come la fonte più credibile di informazioni riguardanti i pazienti. Con la crescente popolarità dei sistemi di IA nella sanità – e presumibilmente con la loro diffusione anche attraverso siti web e app per il mercato consumer – i pazienti potrebbero rivedere questa convinzione.
Sul tipo rapporto che si dovrà instaurare tra medici e algoritmi negli ultimi anni sono stati svolti diversi studi, e si sono espressi molti scrittori e leader del settore. Tutti hanno riconosciuto che non è plausibile (né forse desiderabile) uno scenario in cui le macchine “intelligenti” vengano utilizzate semplicemente per sostituire gli esseri umani nei compiti meno importanti, ma che piuttosto gli esseri umani dovranno imparare a lavorare a stretto contatto con le AI per contribuire insieme, ciascuno con le proprie competenze, a raggiungere i migliori risultati.
Il problema della privacy
Posto inoltre che con l’avvento dei big data uno dei campi esplorati con maggiore interesse ed entusiasmo è quello dei cosiddetti determinanti sociali della salute – ovvero la capacità predittiva che hanno i fattori sociali per le traiettorie di sviluppo del proprio livello di benessere – un altro aspetto che sarà cruciale e che ad oggi è ancora poco discusso è la disponibilità che i pazienti avranno nel voler condividere un gran numero di informazioni personali. Questo aspetto può essere attribuito a molti fattori, tra cui la paura per la propria privacy, la paura per l’affidabilità dei sistemi AI, e la mancanza di trasparenza su come questi dati vengono raccolti e conservati.
Oggi si discute molto delle linee guida etiche che dovremmo adottare per utilizzare l’AI nell’assistenza sanitaria (per chi volesse approfondire il discorso consiglio questo articolo di Audrey Azoulay, direttore generale dell’UNESCO). Una delle principali preoccupazioni per la privacy dei pazienti è senz’altro legata alla quantità di dati generati dai dispositivi per il telemonitoraggio e dalle cartelle cliniche. Questi dati sono già utilizzati da aziende come Google e Amazon con risultati molto interessanti: personalmente ho avuto modo di testare a un AWS Summit ormai qualche anno fa la soluzione AI Amazon Comprehend Medical, e l’impatto che questa può avere sui player del settore è già oggi notevole.
Certo, poiché questo tipo di soluzioni prevedono spesso che le cartelle cliniche vengano caricate nei sistemi di cloud storage delle multinazionali, ci sono notevoli implicazioni in termini di furto di identità e di esfiltrazione dei dati, ma da questo punto di vista qualcosa a livello normativo comincia a muoversi. Negli anni ad esempio sono stati emanati diversi regolamenti sulla privacy del paziente, i più noti dei quali sono l’HIPAA e il GDPR. Questi regolamenti devono però costantemente fare i conti con il trade-off tra la tutela della privacy e la capacità di fare ricerca scientifica. Ci sono ad esempio alcune preoccupazioni su come il GDPR influenzerà l’intelligenza artificiale nell’assistenza sanitaria. La più importante di queste preoccupazioni è che limiterà la condivisione di cartelle cliniche tra i paesi in cui vengono utilizzati sistemi di AI.
Cosa succederà domani?
È sempre difficile fare previsioni, tuttavia credo che la strada che alla fine percorreremo sarà quella di rendere i dati sanitari dei beni comuni. Per farlo dovremo costruire infrastrutture pubbliche e possibilmente comuni (come ad esempio il progetto Gaia X dell’Unione Europea), dove essere ragionevolmente certi che se pagheremo qualcosa in termini di privacy, lo faremo in funzione dell’interesse comune e non dell’interesse di pochi.
Credo che questa prospettiva sia l’unica in grado di farci superare l’impasse che si verrà a creare nei prossimi anni tra il diritto alla privacy e il bisogno di una ricerca scientifica che sia sempre più rapida e accurata.





